| O: O , ou o , é a décima quinta letra do alfabeto latino básico da ISO e a quarta letra da vogal do alfabeto inglês moderno. Seu nome em inglês é o , plural oes . |  |
| P: P , ou p , é a décima sexta letra do alfabeto inglês moderno e do alfabeto latino básico da ISO. Seu nome em inglês é pee , no plural pees . |  |
| Q: Q , ou q , é a décima sétima letra do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é cue , plural cues . |  |
| R: R , ou r , é a décima oitava letra do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é ar , plural ars , ou na Irlanda ou . |  |
| S: S , ou s , é a décima nona letra do alfabeto inglês moderno e do alfabeto latino básico da ISO. Seu nome em inglês é ess , esses plurais. | 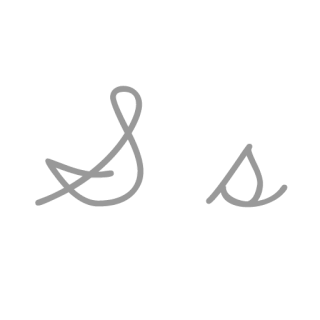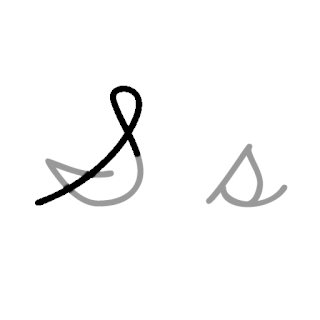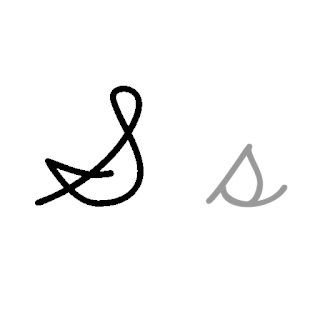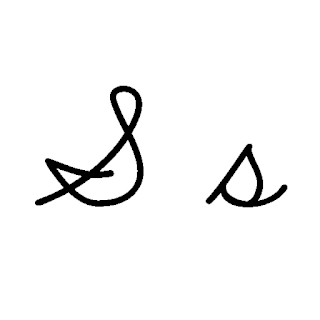 |
| T: T , ou t , é a vigésima letra do alfabeto inglês moderno e do alfabeto latino básico da ISO. Seu nome em inglês é tee , plural tees . É derivado das letras semíticas taw por meio da letra grega τ (tau). Em inglês, é mais comumente usado para representar a plosiva alveolar surda, um som que também denota no alfabeto fonético internacional. É a consoante mais comumente usada e a segunda letra mais comum em textos de língua inglesa. |  |
| U: U , ou u , é a vigésima primeira e a sexta à última letra do alfabeto latino básico ISO e a quinta letra vogal do alfabeto inglês moderno. Seu nome em inglês é u , plural ues . |  |
| V: V , ou v , é a vigésima segunda e a quinta à última letra do alfabeto inglês moderno e do alfabeto latino básico da ISO. Seu nome em inglês é vee , plural vees . |  |
| W: W , ou w , é a vigésima terceira e quarta à última letra do inglês moderno e dos alfabetos latinos básicos ISO. Geralmente representa uma consoante, mas em alguns idiomas representa uma vogal. Seu nome em inglês é double-u , plural double-ues . |  |
| Page break: Uma quebra de página é um marcador em um documento eletrônico que informa ao intérprete do documento que o conteúdo que se segue faz parte de uma nova página. Uma quebra de página faz com que um avanço de página seja enviado à impressora durante o spool do documento para a impressora. Portanto, é um dos elementos que contribui para a paginação. | |
| X: X , ou x , é a vigésima quarta e a terceira à última letra do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é "ex \" , plural exes . |  |
| Y: Y , ou y , é a vigésima quinta e penúltima letra do alfabeto latino básico ISO e a sexta letra vogal do alfabeto inglês moderno. No sistema de escrita inglês, ele representa principalmente uma vogal e raramente uma consoante, e em outras ortografias pode representar uma vogal ou consoante. Seu nome em inglês é wye , plural wyes . | 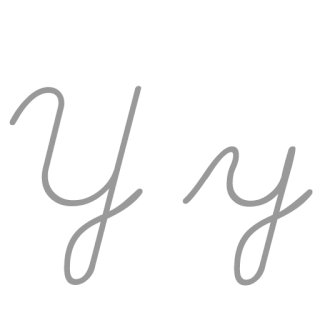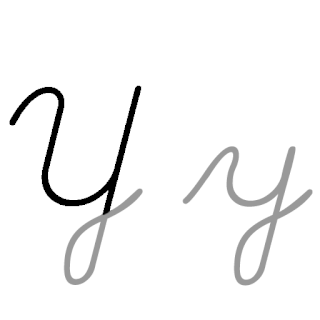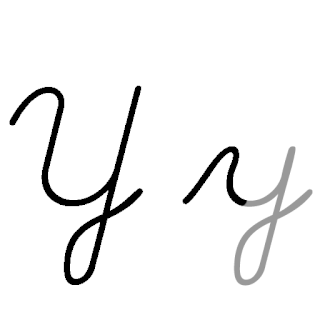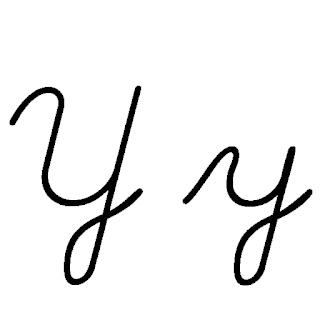 |
| Z: Z , ou z , é a vigésima sexta e última letra do alfabeto inglês moderno e do alfabeto latino básico ISO. Seus nomes usuais em inglês são zed e zee , com uma ocasional variante arcaica izzard . |  |
| Bracket: Um colchete é formado por duas marcas de pontuação altas, frontais ou traseiras, comumente usadas para isolar um segmento de texto ou dados de seus arredores. Normalmente implantado em pares simétricos, um colchete individual pode ser identificado como um colchete esquerdo ou direito ou, alternativamente, um colchete de abertura ou fechamento , respectivamente, dependendo da direcionalidade do contexto. | |
| Vertical bar: A barra vertical é um glifo com vários usos em matemática, computação e tipografia. Tem muitos nomes, muitas vezes relacionados com significados particulares: Sheffer acidente vascular cerebral, tubos, Vbar, vara, linha vertical, barra vertical,, bar, pique ou verti-bar, e diversas variantes sobre esses nomes. Às vezes é considerado uma alografia de barra quebrada . | |
| Bracket: Um colchete é formado por duas marcas de pontuação altas, frontais ou traseiras, comumente usadas para isolar um segmento de texto ou dados de seus arredores. Normalmente implantado em pares simétricos, um colchete individual pode ser identificado como um colchete esquerdo ou direito ou, alternativamente, um colchete de abertura ou fechamento , respectivamente, dependendo da direcionalidade do contexto. | |
| Tilde: O til , ˜ ou ~ , é um grafema com vários usos. O nome do personagem veio do espanhol para o inglês e do português, que por sua vez veio do latim titulus , que significa \ "título \" ou \ "inscrição \". | |
| Delete character: O caractere de controle de exclusão é o último caractere do repertório ASCII, com o código 127. Ele não faz nada e foi projetado para apagar caracteres incorretos na fita de papel. É denotado como ^? em notação circunflexa e é U + 007F em Unicode. | |
| Carriage return: Um retorno de carro , às vezes conhecido como retorno de cartucho e freqüentemente abreviado para CR , <CR> ou retorno , é um caractere de controle ou mecanismo usado para redefinir a posição de um dispositivo para o início de uma linha de texto. Está intimamente associado aos conceitos de alimentação de linha e nova linha, embora possa ser considerado separadamente por direito próprio. | |
| Shift Out and Shift In characters: Shift Out (SO) e Shift In (SI) são caracteres de controle ASCII 14 e 15, respectivamente. Às vezes, eles também são chamados de "Control-N \" e \ "Control-O \". |  |
| Shift Out and Shift In characters: Shift Out (SO) e Shift In (SI) são caracteres de controle ASCII 14 e 15, respectivamente. Às vezes, eles também são chamados de "Control-N \" e \ "Control-O \". | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| ASCII: ASCII , abreviado de American Standard Code for Information Interchange , é um padrão de codificação de caracteres para comunicação eletrônica. Os códigos ASCII representam texto em computadores, equipamentos de telecomunicações e outros dispositivos. A maioria dos esquemas de codificação de caracteres modernos é baseada em ASCII, embora eles suportem muitos caracteres adicionais. | 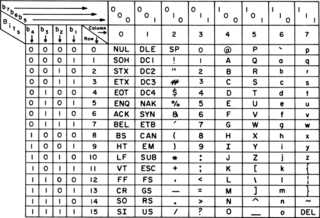 |
| ASCII: ASCII , abreviado de American Standard Code for Information Interchange , é um padrão de codificação de caracteres para comunicação eletrônica. Os códigos ASCII representam texto em computadores, equipamentos de telecomunicações e outros dispositivos. A maioria dos esquemas de codificação de caracteres modernos é baseada em ASCII, embora eles suportem muitos caracteres adicionais. | |
| ASCII: ASCII , abreviado de American Standard Code for Information Interchange , é um padrão de codificação de caracteres para comunicação eletrônica. Os códigos ASCII representam texto em computadores, equipamentos de telecomunicações e outros dispositivos. A maioria dos esquemas de codificação de caracteres modernos é baseada em ASCII, embora eles suportem muitos caracteres adicionais. | |
| ASCII: ASCII , abreviado de American Standard Code for Information Interchange , é um padrão de codificação de caracteres para comunicação eletrônica. Os códigos ASCII representam texto em computadores, equipamentos de telecomunicações e outros dispositivos. A maioria dos esquemas de codificação de caracteres modernos é baseada em ASCII, embora eles suportem muitos caracteres adicionais. | |
| ASCII: ASCII , abreviado de American Standard Code for Information Interchange , é um padrão de codificação de caracteres para comunicação eletrônica. Os códigos ASCII representam texto em computadores, equipamentos de telecomunicações e outros dispositivos. A maioria dos esquemas de codificação de caracteres modernos é baseada em ASCII, embora eles suportem muitos caracteres adicionais. | |
| ASCII: ASCII , abreviado de American Standard Code for Information Interchange , é um padrão de codificação de caracteres para comunicação eletrônica. Os códigos ASCII representam texto em computadores, equipamentos de telecomunicações e outros dispositivos. A maioria dos esquemas de codificação de caracteres modernos é baseada em ASCII, embora eles suportem muitos caracteres adicionais. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| Acknowledgement (data networks): Em redes de dados, telecomunicações e barramentos de computador, uma confirmação ( ACK ) é um sinal que é passado entre processos de comunicação, computadores ou dispositivos para significar confirmação ou recebimento de mensagem, como parte de um protocolo de comunicação. A confirmação negativa é um sinal enviado para rejeitar uma mensagem recebida anteriormente ou para indicar algum tipo de erro. Agradecimentos e confirmações negativas informam o remetente do estado do receptor para que ele possa ajustar seu próprio estado de acordo. | |
| Synchronous Idle: Synchronous Idle ( SYN ) é o caractere de controle ASCII 22 (0x16), representado como ^ V em notação circunflexa. Em EBCDIC, o caractere correspondente é 50 (0x32). Synchronous Idle é usado em alguns sistemas de comunicação serial síncrona, como máquinas Teletype ou o protocolo Binary Synchronous (Bisync) para fornecer um sinal a partir do qual a correção síncrona pode ser alcançada entre o equipamento terminal de dados, particularmente quando nenhum outro caractere está sendo transmitido. | |
| End-of-Transmission-Block character: End-of-Transmission-Block ( ETB ) é um caractere de controle de comunicação usado para indicar o fim de um bloco de dados para fins de comunicação. ETB é usado para segmentar dados em blocos quando a estrutura do bloco não está necessariamente relacionada à função de processamento. | |
| Cancel character: Em telecomunicações, o termo cancelar caractere tem os seguintes significados:
| |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| Substitute character: nUm caractere substituto (␚) é um caractere de controle usado no lugar de um caractere reconhecido como inválido ou incorreto, ou que não pode ser representado em um determinado dispositivo. Também é usado como uma sequência de escape em algumas linguagens de programação. | |
| Escape character: Na computação e nas telecomunicações, um caractere de escape é um caractere que invoca uma interpretação alternativa nos caracteres a seguir em uma sequência de caracteres. Um caractere de escape é um caso particular de metacaracteres. Geralmente, o julgamento de se algo é um caractere de escape ou não depende do contexto. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| End-of-Text character: O caractere End-of-Text ( ETX ) é um caractere de controle usado para informar ao computador receptor que o final de um registro foi atingido. Isso pode ou não ser uma indicação de que todos os dados em um registro foram recebidos. Em ASCII e em EBCDIC, ETX é o ponto de código 0x03, geralmente exibido como ^ C ). | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| C0 and C1 control codes: O código de controle C0 e C1 ou conjuntos de caracteres de controle definem códigos de controle para uso em texto por sistemas de computador que usam ASCII e derivados de ASCII. Os códigos representam informações adicionais sobre o texto, como a posição de um cursor, uma instrução para iniciar uma nova linha ou uma mensagem de que o texto foi recebido. | |
| Space (punctuation): Na escrita, um espaço é uma área em branco que separa palavras, frases, sílabas e outros glifos (caracteres) escritos ou impressos. As convenções de espaçamento variam entre os idiomas e, em alguns idiomas, as regras de espaçamento são complexas. | |
| Exclamation mark: O ponto de exclamação ,! , também às vezes referido como ponto de exclamação , especialmente no inglês americano, é um sinal de pontuação geralmente usado após uma interjeição ou exclamação para indicar sentimentos fortes ou para mostrar ênfase. O ponto de exclamação geralmente marca o final de uma frase, por exemplo: \ "Cuidado! \" Da mesma forma, um ponto de exclamação simples é freqüentemente estabelecido em sinais de aviso. | |
| Quotation mark: As aspas , também conhecidas como aspas , aspas , sinais de fala , aspas invertidas ou sinais de fala , são sinais de pontuação usados em pares em vários sistemas de escrita para desencadear o discurso direto, uma citação ou uma frase. O par consiste em uma aspa de abertura e uma aspa de fechamento, que podem ou não ser o mesmo caractere. | |
| Number sign: O símbolo # é conhecido de várias maneiras nas regiões de língua inglesa como sinal de número , jogo da velha ou jogo da velha . O símbolo tem sido usado historicamente para uma ampla gama de propósitos, incluindo a designação de um número ordinal e como uma abreviatura ligada para libras avoirdupois - tendo sido derivado do agora raro ℔ . | |
| Dollar sign: O sinal de dólar ou peso é um símbolo usado para indicar as unidades de várias moedas ao redor do mundo, especialmente a maioria das moedas denominadas em pesos e dólares. O símbolo pode ter alternadamente um ou dois traços verticais. No uso comum, o sinal aparece à esquerda do valor especificado, por exemplo, "$ 1 \", lido como \ "um dólar \". |  |
| Percent sign: O sinal de porcentagem % é o símbolo usado para indicar uma porcentagem, um número ou proporção como uma fração de 100. Os sinais relacionados incluem o sinal de permille ‰ e o sinal de permiria ‱ , que indicam que um número é dividido por mil ou dez mil, respectivamente. Proporções mais altas usam partes por notação. | |
| Ampersand: O e comercial , também conhecido como o sinal e , é o logograma & , representando a conjunção \ "e \". Originou-se como uma ligadura das letras et —Latin para \ "e \". | |
| Apostrophe: O apóstrofo é um sinal de pontuação e, às vezes, um sinal diacrítico, em idiomas que usam o alfabeto latino e alguns outros alfabetos. Em inglês, é usado para quatro finalidades:
| |
| End-of-Transmission character: Em telecomunicações, um caractere de fim de transmissão ( EOT ) é um caractere de controle de transmissão. Seu uso pretendido é indicar a conclusão de uma transmissão que pode ter incluído um ou mais textos e quaisquer cabeçalhos de mensagens associados. | |
| Bracket: Um colchete é formado por duas marcas de pontuação altas, frontais ou traseiras, comumente usadas para isolar um segmento de texto ou dados de seus arredores. Normalmente implantado em pares simétricos, um colchete individual pode ser identificado como um colchete esquerdo ou direito ou, alternativamente, um colchete de abertura ou fechamento , respectivamente, dependendo da direcionalidade do contexto. | |
| Bracket: Um colchete é formado por duas marcas de pontuação altas, frontais ou traseiras, comumente usadas para isolar um segmento de texto ou dados de seus arredores. Normalmente implantado em pares simétricos, um colchete individual pode ser identificado como um colchete esquerdo ou direito ou, alternativamente, um colchete de abertura ou fechamento , respectivamente, dependendo da direcionalidade do contexto. | |
| Asterisk: O asterisco * , do latim asterisco , do grego antigo ἀστερίσκος, asteriskos , \ "estrelinha \", é um símbolo tipográfico. É assim chamado porque se assemelha à imagem convencional de uma estrela. | |
| Plus and minus signs: Os sinais de mais e menos , + e - , são símbolos matemáticos usados para representar as noções de positivo e negativo, respectivamente. Além disso, + representa a operação de adição, que resulta em uma soma, enquanto - representa a subtração, resultando em uma diferença. Seu uso foi estendido a muitos outros significados, mais ou menos análogos. Mais e menos são termos latinos que significam \ "mais \" e \ "menos \", respectivamente. | |
| Comma: A vírgula, é um sinal de pontuação que aparece em várias versões em diferentes idiomas. Ele tem o mesmo formato de um apóstrofo ou aspas simples em muitos tipos de fontes, mas difere deles por ser colocado na linha de base do texto. Alguns tipos de letra o apresentam como uma linha pequena, ligeiramente curva ou reta, mas inclinada da vertical. Outras fontes dão a ele a aparência de uma miniatura de figura 9 preenchida na linha de base. | |
| Hyphen-minus: O hífen-menos - é o tipo de hífen mais comumente usado, amplamente utilizado em documentos digitais. É o único caractere de hífen disponível no teclado QWERTY. Entre outros usos, conforme explicado no artigo de hífen, pode ser inserido no final de uma linha para quebrar uma palavra no limite de uma sílaba quando a sílaba seguinte é impressa na próxima linha. Em linguagens de programação e planilhas, ele funciona como o sinal de menos. O nome \ "hyphen-minus \" é uma invenção Unicode; o caractere é referido como um hífen ou um sinal de menos de acordo com o contexto em que está sendo usado. Geralmente é chamado de \ "traço \", embora normalmente seja mais curto do que os caracteres de traço. | |
| Full stop: O ponto final, período ou ponto cheio. é um sinal de pontuação. É usado para vários fins, na maioria das vezes para marcar o final de uma frase declarativa; este uso de terminal de frase, por si só, define o sentido mais estrito de ponto final . | |
| Slash (punctuation): A barra é uma marca de pontuação de linha oblíqua inclinada / . Antes usada para marcar pontos e vírgulas, a barra agora é mais frequentemente usada para representar or exclusivo ou inclusivo, divisão e frações e como separador de data. É chamado de solidus em Unicode, também é conhecido como traço oblíquo e tem vários outros nomes históricos ou técnicos, incluindo oblíquo e virgula . | |
| 0: 0 ( zero ) é um número e o dígito numérico usado para representar esse número em numerais. Ele cumpre um papel central na matemática como a identidade aditiva dos inteiros, números reais e muitas outras estruturas algébricas. Como um dígito, 0 é usado como um marcador de posição nos sistemas de valores locais. Os nomes para o número 0 em inglês incluem zero , naught (UK), naught , nil ou - em contextos onde pelo menos um dígito adjacente o distingue da letra "O \" - oh ou o . Termos informais ou de gíria para zero incluem zilch e zip . Ought e aught , bem como a cifra , também foram usados historicamente. | |
| 1: 1 é um número e um dígito numérico usado para representar esse número em numerais. Ele representa uma única entidade, a unidade de contagem ou medida. Por exemplo, um segmento de linha de comprimento unitário é um segmento de linha de comprimento 1. Nas convenções de sinal em que zero não é considerado nem positivo nem negativo, 1 é o primeiro e o menor inteiro positivo. Às vezes também é considerado o primeiro da sequência infinita de números naturais, seguido por 2, embora, por outras definições, 1 seja o segundo número natural, após 0. | |
| Enquiry character: Em comunicações de computador, a investigação é um caractere de controle de transmissão que solicita uma resposta da estação receptora com a qual uma conexão foi estabelecida. Ele representa um sinal destinado a disparar uma resposta na extremidade receptora, para ver se ainda está presente. A resposta, um código de resposta para o terminal que transmitiu o sinal WRU, pode incluir a identificação da estação, o tipo de equipamento em serviço e o status da estação remota. |  |
| 2: 2 ( dois ) é um número, um numeral e um dígito. É o número natural após 1 e precedendo 3. É o menor e único número primo par. Porque forma a base de uma dualidade, tem significado religioso e espiritual em muitas culturas. | |
| 3: 3 ( três ) é um número, um numeral e um dígito. É o número natural que segue 2 e precede 4, é o menor número primo ímpar e o único primo que precede um número quadrado. Tem significado religioso ou cultural em muitas sociedades. | |
| 4: 4 ( quatro ) é um número, um numeral e um dígito. É o número natural após 3 e precedendo 5. É o menor número composto e é considerado azarado em muitas culturas do Leste Asiático. | |
| 5: 5 ( cinco ) é um número, um numeral e um dígito. É o número natural após 4 e precedendo 6, e é um número primo. Alcançou significado ao longo da história em parte porque os humanos típicos têm cinco dígitos em cada mão. | |
| 6: 6 ( seis ) é o número natural após 5 e precedendo 7. É um número composto e o menor número perfeito. | |
| 7: 7 ( sete ) é o número natural após 6 e precedendo 8. É o único número primo antes de um cubo. Muitas vezes é considerado sorte na cultura ocidental e muitas vezes é visto como altamente simbólico. | |
| 8: 8 ( oito ) é o número natural após 7 e antes de 9. | |
| 9: 9 ( nove ) é o número natural após 8 e antes de 10. | |
| Colon (punctuation): Os dois pontos : é uma marca de pontuação que consiste em dois pontos de tamanhos iguais colocados um acima do outro na mesma linha vertical. Os dois pontos geralmente precedem uma explicação, uma lista ou para introduzir uma frase entre aspas. Também é usado entre horas e minutos no tempo, entre certos elementos em citações de periódicos médicos, capítulo e versículo em citações da Bíblia e, nos Estados Unidos, para saudações em cartas comerciais e outras cartas formais. | |
| Semicolon: O ponto e vírgula ou ponto e vírgula ; é um símbolo comumente usado como pontuação ortográfica. Na língua inglesa, um ponto-e-vírgula é mais comumente usado para ligar duas orações independentes que estão intimamente relacionadas no pensamento. Quando um ponto-e-vírgula une duas ou mais ideias em uma frase, essas ideias recebem a mesma classificação. O ponto-e-vírgula também pode ser usado no lugar de vírgulas para separar os itens de uma lista, principalmente quando os elementos dessa lista contêm vírgulas. | |
| Acknowledgement (data networks): Em redes de dados, telecomunicações e barramentos de computador, uma confirmação ( ACK ) é um sinal que é passado entre processos de comunicação, computadores ou dispositivos para significar confirmação ou recebimento de mensagem, como parte de um protocolo de comunicação. A confirmação negativa é um sinal enviado para rejeitar uma mensagem recebida anteriormente ou para indicar algum tipo de erro. Agradecimentos e confirmações negativas informam o remetente do estado do receptor para que ele possa ajustar seu próprio estado de acordo. | |
| Less-than sign: O sinal de menor que é um símbolo matemático que denota uma desigualdade entre dois valores. A forma amplamente adotada de dois traços de comprimento igual conectando-se em um ângulo agudo à esquerda, < , foi encontrada em documentos que datam de 1560. Na escrita matemática, o sinal de menos é normalmente colocado entre dois valores que estão sendo comparados e significa que o primeiro número é menor que o segundo número. Exemplos de uso típico incluem 1 ⁄ 2 <1 e −2 <0 . Desde o desenvolvimento das linguagens de programação de computador, o signo do menos e o do signo foram reaproveitados para uma variedade de usos e operações. | |
| Equals sign: O sinal de igual ou sinal de igual , anteriormente conhecido como sinal de igualdade , é o símbolo matemático = , que é usado para indicar igualdade em algum sentido bem definido. Em uma equação, é colocado entre duas expressões que têm o mesmo valor, ou para as quais se estuda as condições sob as quais têm o mesmo valor. | |
| Greater-than sign: O sinal de maior é um símbolo matemático que denota uma desigualdade entre dois valores. A forma amplamente adotada de dois traços de comprimento igual conectando-se em um ângulo agudo à direita, > , foi encontrada em documentos que datam de 1560. Na escrita matemática, o sinal de maior é normalmente colocado entre dois valores que estão sendo comparados e significa que o primeiro número é maior que o segundo número. Exemplos de uso típico incluem 1,5> 1 e 1> −2 . Desde o desenvolvimento das linguagens de programação de computador, o sinal maior e o menor foram reaproveitados para uma variedade de usos e operações. | |
| Question mark: O ponto de interrogação ? é um sinal de pontuação que indica uma cláusula ou frase interrogativa em muitos idiomas. O ponto de interrogação não é usado para perguntas indiretas. O glifo de ponto de interrogação também é frequentemente usado no lugar de dados ausentes ou desconhecidos. | |
| At sign: O sinal de arroba , @ , normalmente é lido em voz alta como \ "em \"; também é comumente chamado de símbolo arroba , comercial arroba ou sinal de endereço . É usado como uma abreviatura de contabilidade e fatura, significando \ "a uma taxa de \", mas agora é mais amplamente visto em endereços de e-mail e identificadores de plataforma de mídia social. | |
| A: A , ou a , é a primeira letra e a primeira vogal do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é a , plural aes . É semelhante em formato à letra alfa do grego antigo, da qual deriva. A versão em maiúsculas consiste nos dois lados inclinados de um triângulo, cruzados no meio por uma barra horizontal. A versão em minúsculas pode ser escrita em duas formas: a de dois andares a e as de um só ɑ . O último é comumente usado em caligrafia e fontes baseadas nele, especialmente fontes destinadas a serem lidas por crianças, e também é encontrado em itálico. |  |
| B: B , ou b , é a segunda letra do alfabeto latino. Seu nome em inglês é abelha , no plural abelhas . Ele representa a parada bilabial sonora em muitos idiomas, incluindo o inglês. Em algumas outras línguas, é usado para representar outras consoantes bilabiais. | 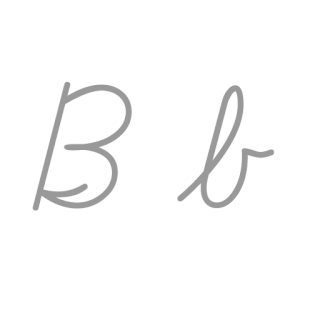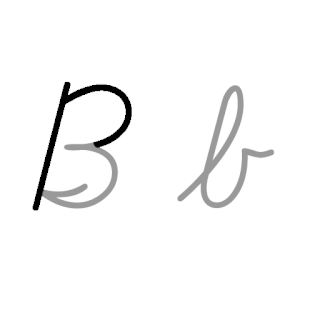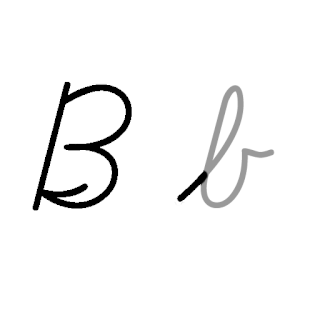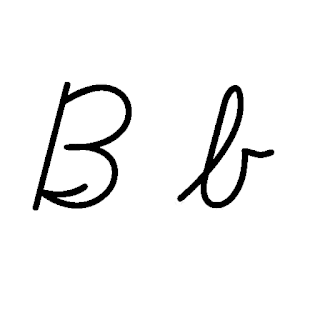 |
| C: C , ou c , é a terceira letra dos alfabetos latinos básicos do inglês e do ISO. Seu nome em inglês é cee , plural cees . |  |
| D: D , ou d , é a quarta letra do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é dee , plural dees . |  |
| E: E , ou e , é a quinta letra e a segunda letra vogal do alfabeto inglês moderno e do alfabeto latino básico do ISO. Seu nome em inglês é e , plural ees . É a letra mais comumente usada em muitos idiomas, incluindo tcheco, dinamarquês, holandês, inglês, francês, alemão, húngaro, latino, letão, norueguês, espanhol e sueco. | 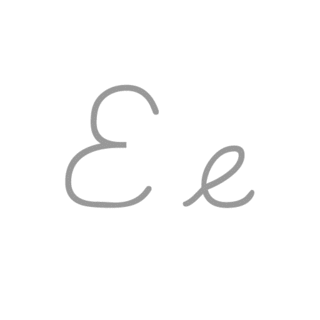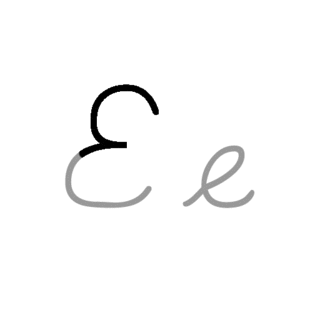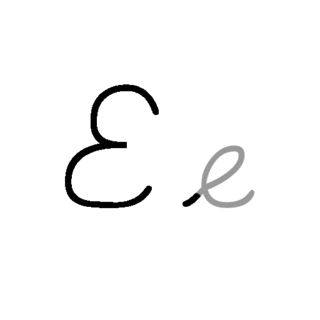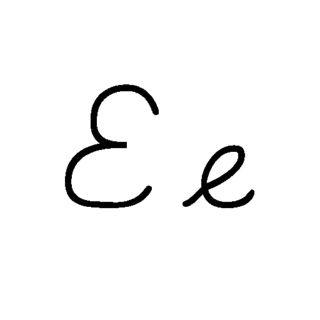 |
| Bell character: Um código de campainha é um código de controle de dispositivo enviado originalmente para tocar uma pequena campainha eletromecânica em tickers e outras impressoras e teletipoas para alertar os operadores do outro lado da linha, geralmente de uma mensagem recebida. Embora os tickers tenham inserido os códigos da campainha em suas fitas, as impressoras geralmente não imprimem um caractere quando o código da campainha é recebido. Os códigos de campainha são geralmente representados pelo rótulo " | |
| F: F , ou f , é a sexta letra do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é ef , e o plural é efs . |  |
| G: G , ou g , é a sétima letra do alfabeto latino básico ISO. Seu nome em inglês é gee , plural gees . | 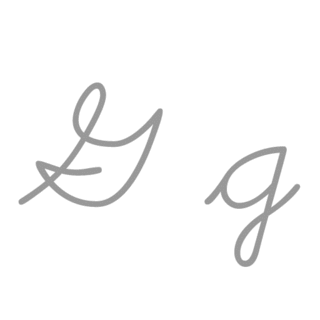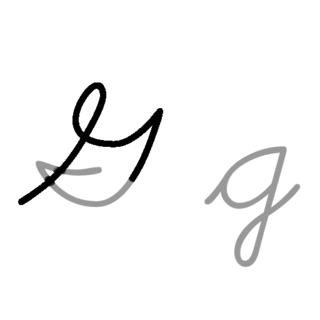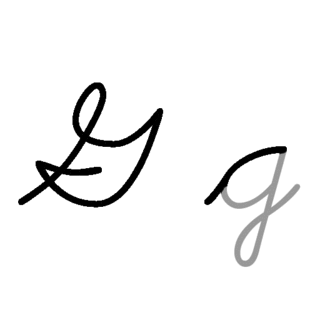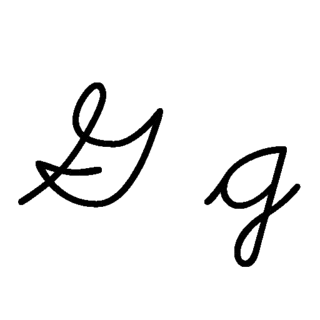 |
| H: H , ou h , é a oitava letra do alfabeto latino básico ISO. Seu nome em inglês é aitch , ou regionalmente haitch . | 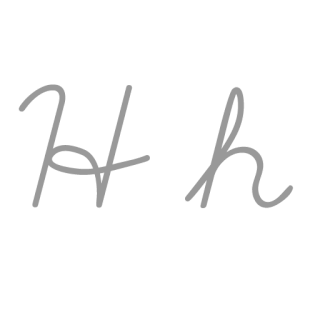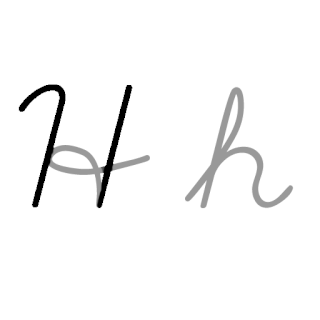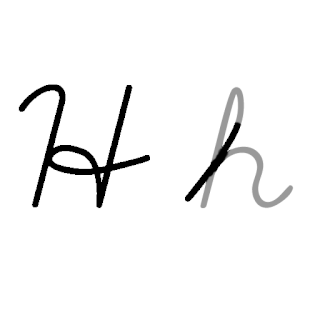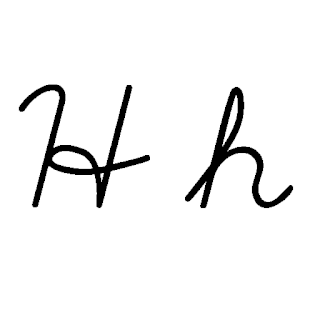 |
| I: I , ou i , é a nona letra e a terceira letra vogal do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é i , plural ies . | 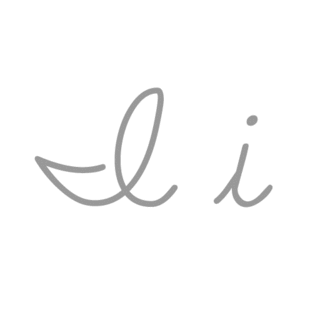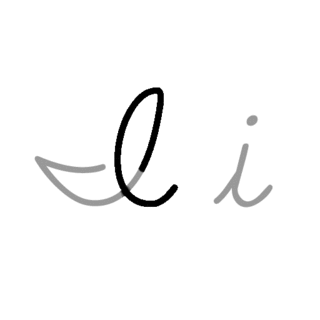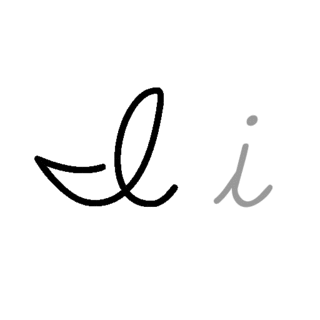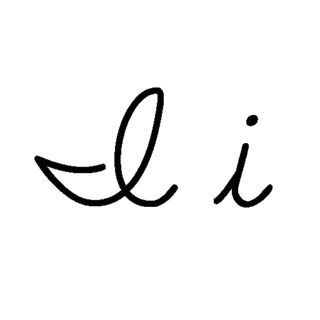 |
| J: J , ou j , é a décima letra do alfabeto inglês moderno e do alfabeto latino básico do ISO. Seu nome usual em inglês é jay , com uma variante jy agora incomum. Quando usado no alfabeto fonético internacional para o som y , pode ser chamado de yod ou jod . | 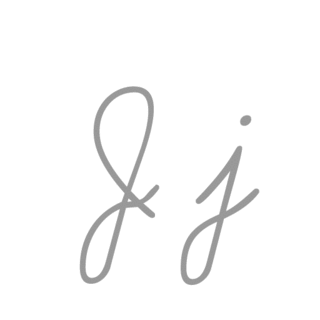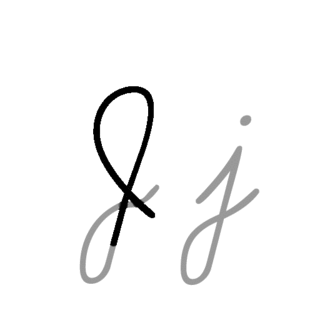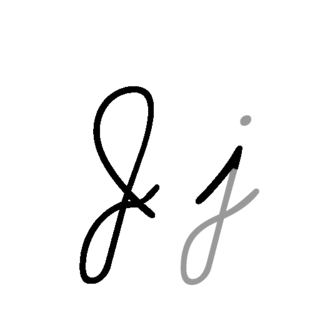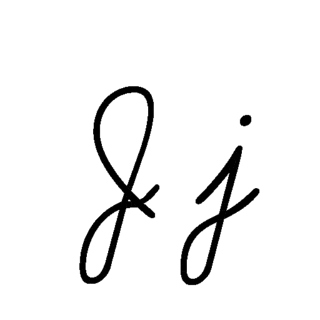 |
| K: K , ou k , é a décima primeira letra do alfabeto inglês moderno e do alfabeto latino básico ISO. Seu nome em inglês é kay , plural kays . A letra K geralmente representa a plosiva velar muda. |  |
| L: L , ou l , é a décima segunda letra do alfabeto inglês moderno e do alfabeto latino básico da ISO. Seu nome em inglês é el , plural els . |  |
| M: M , ou m , é a décima terceira letra do alfabeto inglês moderno e do alfabeto latino básico da ISO. Seu nome em inglês é em , plural ems . | 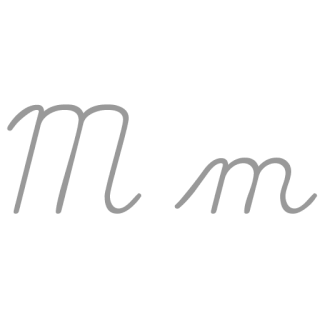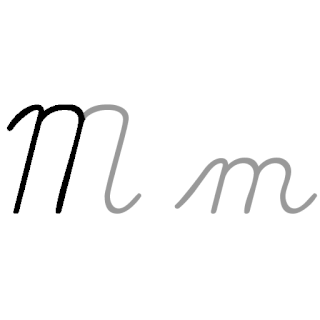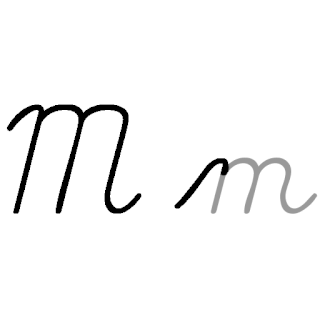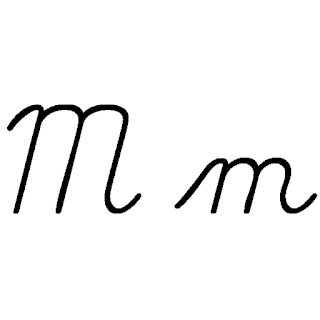 |
Thứ Hai, 5 tháng 7, 2021
M
Đăng ký:
Đăng Nhận xét (Atom)
Aedy Ashraf
Adduci: Adduci é um sobrenome. Pessoas notáveis com o sobrenome incluem: Jim Adduci, jogador de beisebol americano n Jim Adduci,...

-
List of minor planets: 347001–348000: List of minor planets: 347001–348000: List of minor planets: 34001–35000: Timeline of the far fu...
-
35th century BC: O século 35 aC no Oriente Próximo vê a transição gradual do Calcolítico para o início da Idade do Bronze. A protescr...
-
2000 Hamilton Tiger-Cats season: A temporada 2000 do Hamilton Tiger-Cats foi a 43ª para o time na Liga Canadense de Futebol e a 51ª n...

Không có nhận xét nào:
Đăng nhận xét